
داده کاوی فرآیند استخراج و کشف الگوها در مجموعه داده های بزرگ است که شامل روش هایی در محل تلاقی یادگیری ماشین، آمار و سیستم های پایگاه داده است. داده کاوی زیر شاخه ای از علوم کامپیوتر و آمار با هدف کلی استخراج اطلاعات (با روش های هوشمند) از مجموعه داده و تبدیل اطلاعات به یک ساختار قابل درک برای استفاده بیشتر است.
داده کاوی مرحله تجزیه و تحلیل فرایند “کشف دانش در پایگاه های داده” یا KDD است. گذشته از مرحله تجزیه و تحلیل خام، شامل جنبه های مدیریت پایگاه داده و داده ها، پیش پردازش داده ها، ملاحظات مدل و استنباط، معیارهای جالب بودن، ملاحظات پیچیدگی، پس از پردازش ساختارهای کشف شده، تجسم و به روز رسانی آنلاین است.
با توجه به تکامل فناوری انبار داده ها و رشد داده های بزرگ، اتخاذ تکنیک های داده کاوی در چند دهه گذشته به سرعت شتاب گرفته است و با تبدیل داده های خام خود به دانش مفید به شرکت ها کمک می کند. با این حال، علیرغم این واقعیت که این فناوری به طور مداوم برای مدیریت داده ها در مقیاس بزرگ تکامل می یابد، رهبران هنوز درمورد مقیاس پذیری و اتوماسیون با چالش هایی روبرو هستند.
تکنیک های داده کاوی که زیربنای این تجزیه و تحلیل ها هستند را می توان به دو هدف اصلی تقسیم کرد. آنها می توانند مجموعه داده هدف را توصیف کنند یا می توانند نتایج را با استفاده از الگوریتم های یادگیری ماشین پیش بینی کنند. این روشها برای سازماندهی و فیلتر کردن داده ها، ظاهر شدن جالب ترین اطلاعات، از کشف تقلب گرفته تا رفتارهای کاربر، تنگناها و حتی نقض امنیت استفاده می شود.
تفاوت بین تجزیه و تحلیل داده ها و داده کاوی در این است که تجزیه و تحلیل داده ها برای آزمایش مدل ها و فرضیه ها روی مجموعه داده استفاده می شود، به عنوان مثال، تجزیه و تحلیل اثربخشی یک کمپین بازاریابی، صرف نظر از میزان داده ها. در مقابل، داده کاوی از یادگیری ماشین و مدل های آماری برای کشف الگوهای مخفی یا پنهان در حجم زیادی از داده ها استفاده می کند.
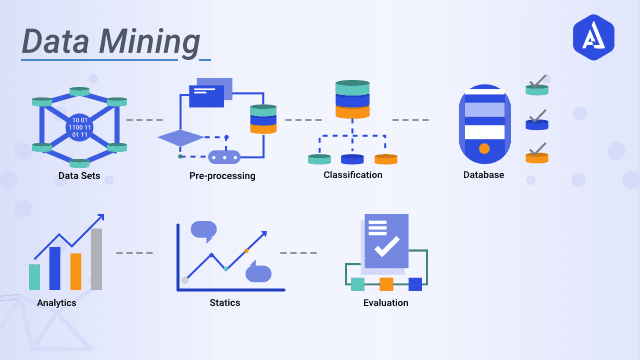
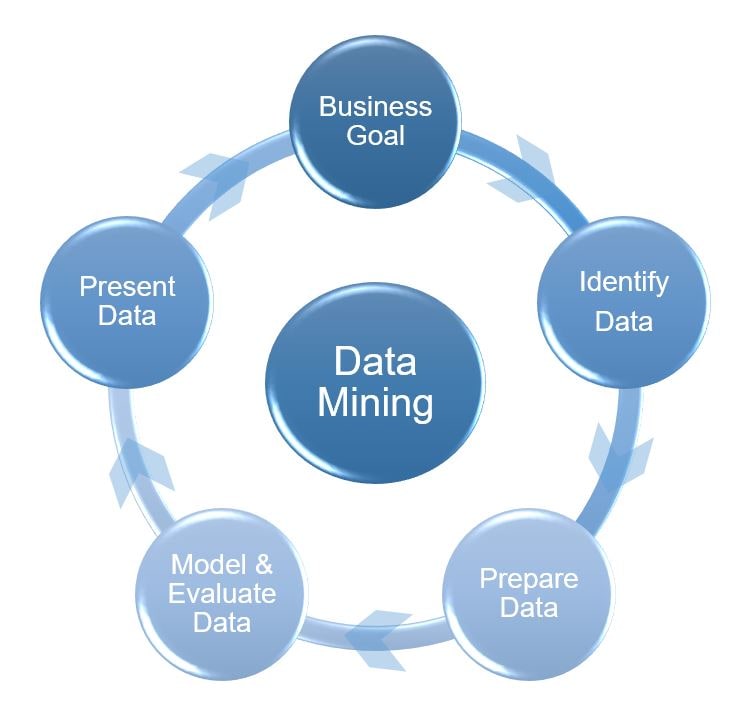
فرآیند داده کاوی شامل چندین مرحله از جمع آوری داده ها تا تجسم برای استخراج اطلاعات ارزشمند از مجموعه داده های بزرگ است. همانطور که در بالا ذکر شد، تکنیک های داده کاوی برای ایجاد توصیف و پیش بینی در مورد مجموعه داده هدف استفاده می شود. دانشمندان داده ها را از طریق مشاهده الگوها، ارتباطات و همبستگی ها توصیف می کنند. آنها همچنین داده ها را از طریق روش های طبقه بندی و رگرسیون طبقه بندی و دسته بندی می کنند. داده کاوی معمولاً شامل چهار مرحله اصلی است: تعیین اهداف، جمع آوری و آماده سازی داده ها، بکارگیری الگوریتم های داده کاوی و ارزیابی نتایج.
برنامه های داده کاوی روابط و الگوهای داده ها را بر اساس درخواست کاربران تجزیه و تحلیل می کنند. به عنوان مثال، یک شرکت می تواند از نرم افزار داده کاوی برای ایجاد کلاس اطلاعات استفاده کند. برای مثال، تصور کنید که یک رستوران می خواهد از داده کاوی برای تعیین زمان ارائه موارد خاص استفاده کند. اطلاعاتی را که جمع آوری کرده است بررسی می کند و بر اساس زمان مراجعه مشتریان و سفارش آنها کلاس ایجاد می کند.
یکی از پردرآمدترین کاربردهای داده کاوی، استفاده از رسانه های اجتماعی بوده است. پلتفرم هایی مانند فیس بوک، تیک تاک، اینستاگرام و توییتر مجموعه ای از داده ها را در مورد کاربران جداگانه جمع آوری می کنند تا درباره ترجیحات خود استنباط کنند تا تبلیغات بازاریابی هدفمند ارسال شود. این داده ها همچنین برای تأثیرگذاری بر رفتار کاربران و تغییر ترجیحات آنها، چه برای یک محصول مصرفی و چه کسانی که در انتخابات رای می دهند، مورد استفاده قرار می گیرد.
داده کاوی با استفاده از الگوریتم ها و تکنیک های مختلف حجم زیادی از داده ها را به اطلاعات مفید تبدیل می کند. در اینجا به 4 مورد از برخی از رایج ترین آنها اشاره شده است:
قوانین ارتباط: یک قانون ارتباط یک روش مبتنی بر قاعده برای یافتن روابط بین متغیرها در یک مجموعه داده معین است. این روش ها اغلب برای تجزیه و تحلیل سبد بازار استفاده می شود و به شرکت ها اجازه می دهد روابط بین محصولات مختلف را بهتر درک کنند. درک عادات مصرف مشتریان، مشاغل را قادر می سازد تا استراتژی های فروش متقابل و موتورهای توصیه بهتری را توسعه دهند.
شبکه های عصبی: در درجه اول برای الگوریتم های یادگیری عمیق، شبکه های عصبی با شبیه سازی ارتباط متقابل مغز انسان از طریق لایه های گره، داده های آموزشی را پردازش می کنند. هر گره از ورودی ها، وزن ها، یک سوگیری (یا آستانه) و یک خروجی تشکیل شده است. اگر این مقدار خروجی از یک آستانه مشخص فراتر رود، گره را “روشن” یا فعال می کند و داده ها را به لایه بعدی شبکه منتقل می کند. شبکه های عصبی این عملکرد نگاشت را از طریق یادگیری تحت نظارت یاد می گیرند و بر اساس عملکرد از دست دادن از طریق فرایند شیب نزولی تنظیم می شوند. وقتی تابع هزینه در صفر یا نزدیک به صفر باشد، می توانیم از صحت مدل اطمینان داشته باشیم تا پاسخ درست را ارائه دهیم.
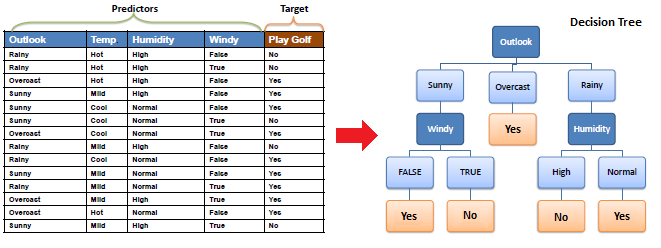
درخت تصمیم گیری: این تکنیک داده کاوی از روش های طبقه بندی یا رگرسیون برای طبقه بندی یا پیش بینی نتایج احتمالی بر اساس مجموعه ای از تصمیمات استفاده می کند. همانطور که از نامش پیداست، از تجسم درخت مانند برای نشان دادن نتایج احتمالی این تصمیمات استفاده می کند.
K- نزدیکترین همسایه(KNN) : – نزدیکترین همسایه، همچنین به عنوان الگوریتم KNN شناخته می شود، یک الگوریتم غیر پارامتری است که نقاط داده را بر اساس مجاورت و ارتباط آنها با سایر داده های موجود طبقه بندی می کند. این الگوریتم فرض می کند که نقاط داده مشابه را می توان در نزدیکی یکدیگر یافت. در نتیجه، به دنبال محاسبه فاصله بین نقاط داده، معمولاً از طریق فاصله اقلیدسی، و سپس بر اساس متداول ترین رده یا میانگین، طبقه ای را تعیین می کند.